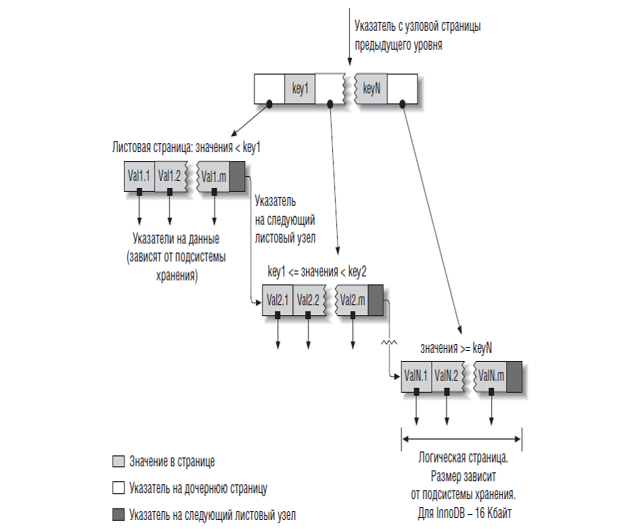
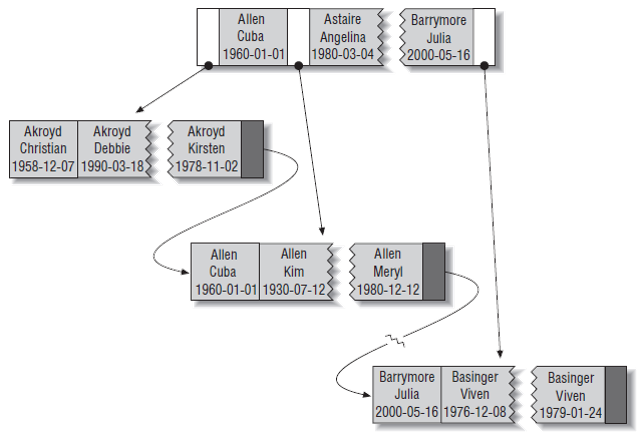
Индексирование btree
CREATE TABLE people (
last_name TEXT NOT NULL,
first_name TEXT NOT NULL,
dob TIMESTAMP NOT NULL,
gender INT NOT NULL
);
CREATE INDEX idx_people_name
ON people USING btree
(last_name, first_name, dob);CREATE TEMPORARY TABLE testhash (
fname TEXT NOT NULL,
lname TEXT NOT NULL
);
CREATE INDEX idx_testhash_fname
ON testhash USING hash (fname);| fname | lname |
|---|---|
| Arjen | Lentz |
| Baron | Schwartz |
| Peter | Zaitsev |
| Vadim | Tkachenko |
f('Arjen') = 2323
f('Baron') = 7437
f('Peter') = 8784
f('Vadim') = 2458| Ячейка | Значение |
|---|---|
| 2323 | Указатель на строку 1 |
| 2458 | Указатель на строку 4 |
| 7437 | Указатель на строку 2 |
| 8784 | Указатель на строку 3 |
SELECT lname FROM testhash WHERE fname = 'Peter';В PostgreSQL до 10 версии hash-индекс не записывается в WAL-лог, т. е. он не транзакционен.
CREATE TABLE city (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
area polygon
);
CREATE INDEX idx_city_area
ON city USING gist (area);
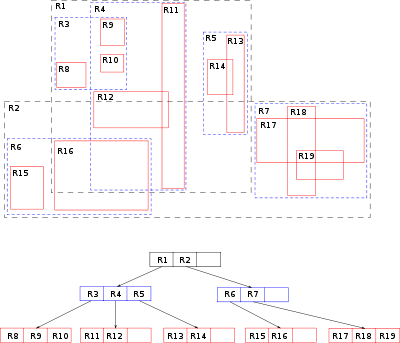
В PostgreSQL GiST позволяет создать для любого собственного типа данных индекс основанный на R-Tree.
CREATE TABLE movies (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
genres TEXT[] NOT NULL
);
CREATE INDEX idx_movies_genres
ON movies USING gin (genres);
| id | title | genres |
|---|---|---|
| 1 | Toy Story | {'Animation', 'Children', 'Comedy'} |
| 589 | Terminator 2: Judgment Day | {'Action', 'Sci-Fi'} |
| 741 | Ghost in the Shell | {'Animation', 'Sci-Fi'} |
| 45517 | Cars | {'Animation', 'Children', 'Comedy'} |
| key | ids |
|---|---|
| Action | 589 |
| Animation | 1, 741, 45517 |
| Children | 1, 45517 |
| Comedy | 1, 45517 |
| Sci-Fi | 589, 741 |
| id | name | gender |
|---|---|---|
| 1 | Иван | Мужской |
| 2 | Евгений | Мужской |
| 3 | Александра | Женский |
| 4 | Петр | Мужской |
| 5 | Мария | Женский |
| value | first-id | bitmask |
|---|---|---|
| Женский | 1 | 00101 |
| Мужской | 1 | 11010 |
CREATE TABLE items (
id BIGSERIAL PRIMARY KEY,
avatar_id INT NULL,
mail_id INT NULL,
auction_id INT NULL,
...
CHECK (
CASE WHEN avatar_id IS NULL THEN 1 ELSE 0 END +
CASE WHEN mail_id IS NULL THEN 1 ELSE 0 END +
CASE WHEN auction_id IS NULL THEN 1 ELSE 0 END = 1
)
);
CREATE INDEX idx_items_avatar_id ON items (avatar_id)
WHERE avatar_id IS NOT NULL;
CREATE INDEX idx_items_mail_id ON items (mail_id)
WHERE mail_id IS NOT NULL;
CREATE INDEX idx_items_auction_id ON items (auction_id)
WHERE auction_id IS NOT NULL;CREATE TABLE movies (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
genres TEXT[] NOT NULL
);
CREATE INDEX idx_movies_title
ON movies (LOWER(title));
SELECT * FROM movies
WHERE title = 'Alice in Wonderland';
SELECT * FROM movies
WHERE LOWER(title) = LOWER('Alice in Wonderland');
CREATE TABLE movies (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL
);
CLUSTER movies USING movies_pkey;
CLUSTER movies;
CLUSTER;
Кластерный индекс (или кластерный ключ) сохраняет не только значения колонки в отсортированном виде, а и данные всей строки.
Это позволяет минимизировать количество операций чтения с диска при работе с таким индексом. В таблице может быть только один кластерный индекс.
CREATE TABLE movies (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL
);
CREATE INDEX idx_movies_title ON movies (title);
SELECT title FROM movies
WHERE title = 'Alice in Wonderland';
Покрывающий индекс содержит все данные, необходимые для выполнения запроса.
В PostgreSQL индексы не хранят информацию о видимости записи для MVCC. Из-за этого они могут быть покрывающими только если в таблице нет мертвых кортежей.

CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ]
[ [ IF NOT EXISTS ] имя ] ON имя_таблицы [ USING метод ]
( { имя_столбца | ( выражение ) }
[ COLLATE правило_сортировки ] [ класс_операторов ]
[ ASC | DESC ] [ NULLS { FIRST | LAST } ]
[, ...]
)
[ WITH ( параметр_хранения = значение [, ... ] ) ]
[ TABLESPACE табл_пространство ]
[ WHERE предикат ]
CREATE INDEX test_index ON test_table (col varchar_pattern_ops);
Класс_операторов:
Для примеров в данной лекции используется база рейтингов кинофильмов.
С сайта movielens используются файлы:
| Таблица | Кортежей | Размер |
|---|---|---|
| genres | 19 | 48 kB |
| links | 40 110 | 2 944 kB |
| movie_genres | 74 229 | 4 856 kB |
| movie_tags | 668 953 | 49 152 kB |
| movies | 40 110 | 3 400 kB |
| rating | 24 404 096 | 1 971 200 kB |
| genres | 49 657 | 5 344 kB |
Обзщий размер: ~1995MB
FOREIGN KEY объявлены, но никакие индексы не создавались.
select m.id, m.title, avg(r.rating)
from movies m
join movie_genres gm on (gm.movie_id = m.id)
join genres g on (g.id = gm.genre_id)
join movie_tags tm on (tm.movie_id = m.id)
join tags t on (t.id = tm.tag_id)
join ratings r on (r.movie_id = m.id)
where lower(g.name) = lower('Comedy')
and lower(t.name) like lower('Zombie%')
group by m.id, m.title
order by avg(r.rating) desc;
Total query runtime: 7.7 secs
60 строк получено.
select * from movies;Данный запрос идет по всей таблице с фильмами и возвращает их в качестве результата.
select * from movies where title = 'Alice in Wonderland';Данный запрос идет по всей таблице с фильмами и возвращает из них, только те, у которых название 'Alice in Wonderland'.
В данном случае он просмотрит более 40 000 строк, чтобы найти 8 фильмов.
create index idx_movies_title on movies (title);
select * from movies where title = 'Alice in Wonderland';Данный запрос идет по индексу и находит фильмы с названием 'Alice in Wonderland'.
В данном случае он просмотрит 8 записей, чтобы найти 8 фильмов.
select * from movies where title <> 'Alice in Wonderland';Данный запрос не будет использовать индекс и просмотрит всю таблицу.
create index idx_movies_title on movies (title);
create index idx_movies_year on movies (year);
select * from movies where title = 'Alice in Wonderland'
and year = 1999;create index idx_movies_title on movies (title);
create index idx_movies_year on movies (year);
select * from movies where title = 'Alice in Wonderland'
order by year;
select * from movies where title <> 'Alice in Wonderland'
order by year;create index idx_movies_ty on movies (title, year);
create index idx_movies_yt on movies (year, title);
select * from movies where title = 'Alice in Wonderland'
order by year;
select * from movies where title <> 'Alice in Wonderland'
order by year;create index idx_movie_genre_movie_id
on movie_genres (movie_id);
-- 1000 rows
select * from movies m
join movie_genres g on m.id = g.movie_id
limit 1000;
-- over 70 000 rows
select * from movies m
join movie_genres g on m.id = g.movie_id;
# postgresql.conf
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.max = 10000
pg_stat_statements.track = all
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
SELECT pg_stat_statements_reset();
...
SELECT * FROM pg_stat_statements;bench=# \x
bench=# SELECT query, calls, total_time, rows, 100.0 * shared_blks_hit /
nullif(shared_blks_hit + shared_blks_read, 0) AS hit_percent
FROM pg_stat_statements ORDER BY total_time DESC LIMIT 3;
-[ RECORD 1 ]---------------------------------------------------------------------
query | UPDATE pgbench_branches SET bbalance = bbalance + ? WHERE bid = ?;
calls | 3000
total_time | 9609.00100000002
rows | 2836
hit_percent | 99.9778970000200936
-[ RECORD 2 ]---------------------------------------------------------------------
query | UPDATE pgbench_tellers SET tbalance = tbalance + ? WHERE tid = ?;
calls | 3000
total_time | 8015.156
rows | 2990
hit_percent | 99.9731126579631345
-[ RECORD 3 ]---------------------------------------------------------------------
query | copy pgbench_accounts from stdin
calls | 1
total_time | 310.624
rows | 100000
hit_percent | 0.30395136778115501520log_duration = on
log_min_duration_statement = 50set log_min_duration_statement = 50;
select * from movies where title = 'Alice in Wonderland';
2017-03-12 22:34:32 MSK [8960-5] postgres@movielens LOG: duration: 50.157 ms statement: select * from movies where title = 'Alice in Wonderland'2017-03-12 22:35:42 MSK [8960-6] postgres@movielens LOG: duration: 54.305 ms statement: select * from movies where title = 'Alice in Wonderland'
log_duration = on
log_lock_waits = on
log_min_duration_statement = 50
log_filename = 'postgresql-%Y-%m-%d_%H%M%S'
log_directory = '/var/log/postgresql'
log_destination = 'csvlog'
logging_collector = on
Логирование в CSV создаёт файлы в формате, пригодном для анализа утилитами вида pgbadger:
sudo apt instal libtext-csv-xs-perl pgbadger
pgbadger /var/log/postgresql/*.csvПериодические выполняемые пакетные задания действительно могут запускать долго выполняющиеся запросы, но обычные запросы не должны занимать много времени.
Ищите запросы, которые потребляют большую часть времени сервера. Напомним, что короткие запросы, выполняемые очень часто, тоже могут занимать много времени.
Ищите запросы, которых вчера не было в первой сотне, а сегодня они появились. Это могут быть новые запросы или запросы, которые обычно выполнялись быстро, а теперь замедлились из-за изменившейся схемы индексации. Либо произошли еще какие-то изменения.
EXPLAIN [ ( параметр [, ...] ) ] оператор
EXPLAIN [ ANALYZE ] [ VERBOSE ] оператор
Здесь допускается параметр:
ANALYZE [ boolean ]
VERBOSE [ boolean ]
COSTS [ boolean ]
BUFFERS [ boolean ]
TIMING [ boolean ]
FORMAT { TEXT | XML | JSON | YAML }
BEGIN;
EXPLAIN ANALYZE ...;
ROLLBACK;CREATE TABLE foo (c1 integer, c2 text);
INSERT INTO foo
SELECT i, md5(random()::text)
FROM generate_series(1, 1000000) AS i;
EXPLAIN SELECT * FROM foo;
QUERY PLAN
--------------------------------------------------------------
Seq Scan on foo (cost=0.00..18334.00 rows=1000000 width=37)
(1 строка)
INSERT INTO foo
SELECT i, md5(random()::text)
FROM generate_series(1, 10) AS i;
EXPLAIN SELECT * FROM foo;
QUERY PLAN
--------------------------------------------------------------
Seq Scan on foo (cost=0.00..18334.00 rows=1000000 width=37)
(1 строка)
ANALYZE foo;
EXPLAIN SELECT * FROM foo;
QUERY PLAN
--------------------------------------------------------------
Seq Scan on foo (cost=0.00..18334.10 rows=1000010 width=37)
(1 строка)
EXPLAIN ANALYZE SELECT * FROM foo;
QUERY PLAN
--------------------------------------------------------------
Seq Scan on foo (cost=0.00..18334.10 rows=1000010 width=37)
(actual time=0.013..89.291 rows=1000010 loops=1)
Planning time: 0.040 ms
Execution time: 123.611 ms
(3 строки)
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
QUERY PLAN
-------------------------------------------------------------
Seq Scan on foo (cost=0.00..20834.12 rows=999514 width=37)
Filter: (c1 > 500)
(2 строки)
CREATE INDEX ON foo(c1);
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
QUERY PLAN
-------------------------------------------------------------
Seq Scan on foo (cost=0.00..20834.12 rows=999507 width=37)
Filter: (c1 > 500)
(2 строки)
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using foo_c1_idx on foo (cost=0.42..25.23 rows=503 width=37)
Index Cond: (c1 < 500)
(2 строки)
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';
QUERY PLAN
------------------------------------------------------------------------
Index Scan using foo_c1_idx on foo (cost=0.42..26.49 rows=1 width=37)
Index Cond: (c1 < 500)
Filter: (c2 ~~ 'abcd%'::text)
(3 строки)
EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';
QUERY PLAN
----------------------------------------------------------
Seq Scan on foo (cost=0.00..20834.12 rows=100 width=37)
Filter: (c2 ~~ 'abcd%'::text)
(2 строки)
CREATE INDEX ON foo(c2);
EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';
QUERY PLAN
----------------------------------------------------------
Seq Scan on foo (cost=0.00..20834.12 rows=100 width=37)
Filter: (c2 ~~ 'abcd%'::text)
(2 строки)
CREATE INDEX ON foo(c2 text_pattern_ops);
EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';
QUERY PLAN
---------------------------------------------------------------------------
Bitmap Heap Scan on foo (cost=4.57..51.35 rows=100 width=37)
Filter: (c2 ~~ 'abcd%'::text)
-> Bitmap Index Scan on foo_c2_idx1 (cost=0.00..4.54 rows=12 width=0)
Index Cond: ((c2 ~>=~ 'abcd'::text) AND (c2 ~<~ 'abce'::text))
(4 строки)
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;
QUERY PLAN
------------------------------------------------------------------------------
Index Only Scan using foo_c1_idx on foo (cost=0.42..25.23 rows=503 width=4)
Index Cond: (c1 < 500)
(2 строки)
DROP INDEX foo_c1_idx;
EXPLAIN SELECT * FROM foo ORDER BY c1;
QUERY PLAN
--------------------------------------------------------------------
Sort (cost=145338.51..147838.54 rows=1000010 width=37)
Sort Key: c1
-> Seq Scan on foo (cost=0.00..18334.10 rows=1000010 width=37)
(3 строки)
CREATE INDEX ON foo(c1);
EXPLAIN SELECT * FROM foo ORDER BY c1;
QUERY PLAN
---------------------------------------------------------------------------------
Index Scan using foo_c1_idx on foo (cost=0.42..34317.58 rows=1000010 width=37)
(1 строка)
CREATE TABLE bar (c1 integer, c2 boolean);
INSERT INTO bar
SELECT i, i%2=1
FROM generate_series(1, 500000) AS i;
ANALYZE bar;
EXPLAIN SELECT * FROM foo JOIN bar ON foo.c1=bar.c1 LIMIT 10000;
QUERY PLAN
-----------------------------------------------------------------------------
Limit (cost=15417.00..16310.28 rows=10000 width=42)
-> Hash Join (cost=15417.00..60081.14 rows=500000 width=42)
Hash Cond: (foo.c1 = bar.c1)
-> Seq Scan on foo (cost=0.00..18334.10 rows=1000010 width=37)
-> Hash (cost=7213.00..7213.00 rows=500000 width=5)
-> Seq Scan on bar (cost=0.00..7213.00 rows=500000 width=5)
(6 строк)
CREATE INDEX ON bar(c1);
EXPLAIN SELECT * FROM foo JOIN bar ON foo.c1=bar.c1 LIMIT 10000;
QUERY PLAN
----------------------------------------------------------------------------------
Limit (cost=0.42..9654.15 rows=10000 width=42)
-> Nested Loop (cost=0.42..482686.60 rows=500000 width=42)
-> Seq Scan on foo (cost=0.00..18334.10 rows=1000010 width=37)
-> Index Scan using bar_c1_idx on bar (cost=0.42..0.45 rows=1 width=5)
Index Cond: (c1 = foo.c1)
(5 строк)
select distinct m.id, m.title
from movies m
join movie_genres gm on (gm.movie_id = m.id)
join genres g on (g.id = gm.genre_id)
join movie_tags tm on (tm.movie_id = m.id)
join tags t on (t.id = tm.tag_id)
where lower(g.name) = lower('Comedy')
and lower(t.name) = lower('Zombie');
Total query runtime: 182 msec
21 строка получена.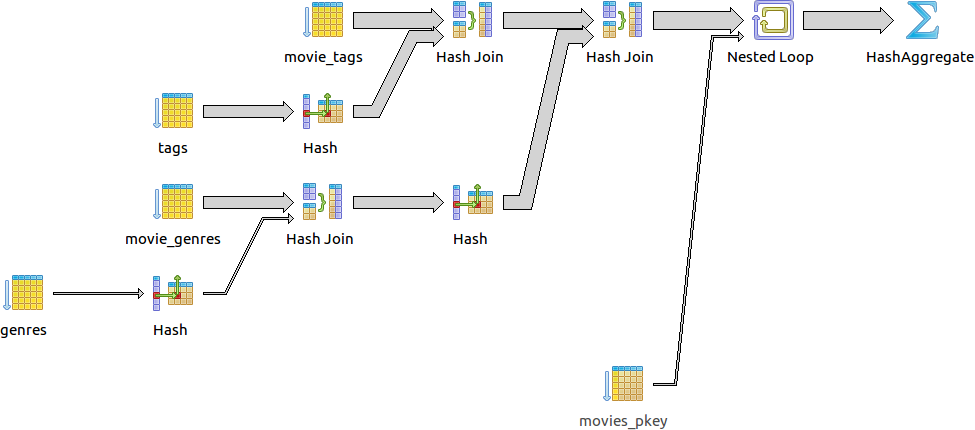
QUERY PLAN
----------------------------------------------------------------------------------------------------
HashAggregate (cost=16212.83..16216.83 rows=400 width=24)
Group Key: m.id, m.title
-> Nested Loop (cost=2573.10..16210.83 rows=400 width=24)
Join Filter: (gm.movie_id = m.id)
-> Hash Join (cost=2572.81..16081.85 rows=400 width=8)
Hash Cond: (tm.movie_id = gm.movie_id)
-> Hash Join (cost=1060.95..14553.47 rows=3341 width=4)
Hash Cond: (tm.tag_id = t.id)
-> Seq Scan on movie_tags tm (cost=0.00..10950.53 rows=668953 width=8)
-> Hash (cost=1057.86..1057.86 rows=248 width=4)
-> Seq Scan on tags t (cost=0.00..1057.86 rows=248 width=4)
Filter: (lower(name) = 'zombie'::text)
Rows Removed by Filter: 49655
-> Hash (cost=1463.02..1463.02 rows=3907 width=4)
-> Hash Join (cost=1.30..1463.02 rows=3907 width=4)
Hash Cond: (gm.genre_id = g.id)
-> Seq Scan on movie_genres gm (cost=0.00..1144.29 rows=74229 width=8)
-> Hash (cost=1.28..1.28 rows=1 width=4)
-> Seq Scan on genres g (cost=0.00..1.28 rows=1 width=4)
Filter: (lower(name) = 'comedy'::text)
-> Index Scan using movies_pkey on movies m (cost=0.29..0.31 rows=1 width=24)
Index Cond: (id = tm.movie_id)
(21 rows)
CREATE INDEX idx_links_movie_id ON links (movie_id);
CREATE INDEX idx_movie_genres_genre_id ON movie_genres (genre_id);
CREATE INDEX idx_movie_genres_movie_id ON movie_genres (movie_id);
CREATE INDEX idx_movie_tags_tag_id ON movie_tags (tag_id);
CREATE INDEX idx_movie_tags_movie_id ON movie_tags (movie_id);
CREATE INDEX idx_ratings_movie_id ON ratings (movie_id);
CREATE INDEX idx_movies_title ON movies (LOWER(title) text_pattern_ops);
CREATE INDEX idx_genres_name ON genres (LOWER(name) text_pattern_ops);
CREATE INDEX idx_tags_name ON tags (LOWER(name) text_pattern_ops);
ANALYZE;
select distinct m.id, m.title
from movies m
join movie_genres gm on (gm.movie_id = m.id)
join genres g on (g.id = gm.genre_id)
join movie_tags tm on (tm.movie_id = m.id)
join tags t on (t.id = tm.tag_id)
where lower(g.name) = lower('Comedy')
and lower(t.name) = lower('Zombie');
Total query runtime: 12 msec
21 строка получена.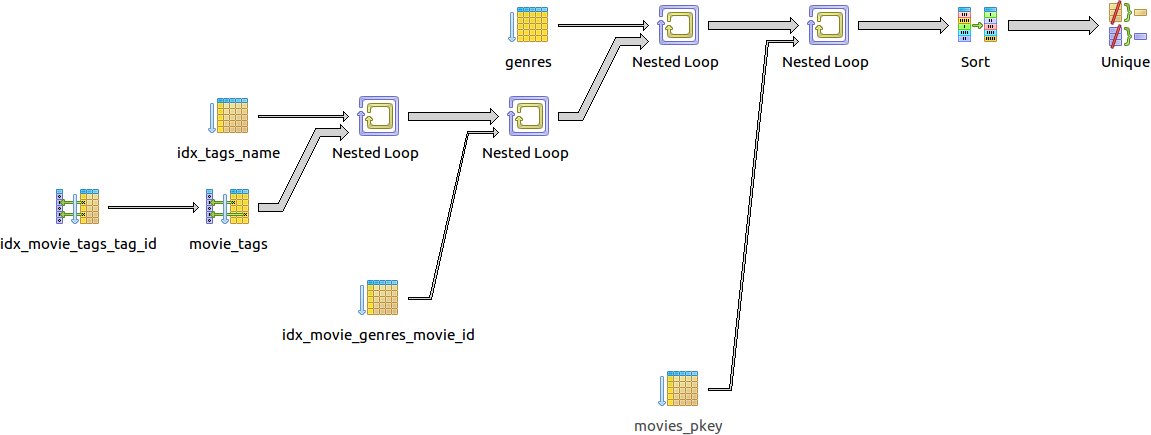
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------
Unique (cost=271.50..271.51 rows=2 width=24)
-> Sort (cost=271.50..271.50 rows=2 width=24)
Sort Key: m.id, m.title
-> Nested Loop (cost=5.96..271.49 rows=2 width=24)
Join Filter: (gm.movie_id = m.id)
-> Nested Loop (cost=5.67..270.84 rows=2 width=8)
Join Filter: (gm.genre_id = g.id)
-> Seq Scan on genres g (cost=0.00..1.28 rows=1 width=4)
Filter: (lower(name) = 'comedy'::text)
-> Nested Loop (cost=5.67..269.17 rows=31 width=12)
-> Nested Loop (cost=5.37..264.60 rows=13 width=4)
-> Index Scan using idx_tags_name on tags t (cost=0.41..8.43 rows=1 width=4)
Index Cond: (lower(name) = 'zombie'::text)
-> Bitmap Heap Scan on movie_tags tm (cost=4.96..255.48 rows=69 width=8)
Recheck Cond: (tag_id = t.id)
-> Bitmap Index Scan on idx_movie_tags_tag_id (cost=0.00..4.94 rows=69 width=0)
Index Cond: (tag_id = t.id)
-> Index Scan using idx_movie_genres_movie_id on movie_genres gm (cost=0.29..0.33 rows=2 width=8)
Index Cond: (movie_id = tm.movie_id)
-> Index Scan using movies_pkey on movies m (cost=0.29..0.31 rows=1 width=24)
Index Cond: (id = tm.movie_id)
(21 rows)
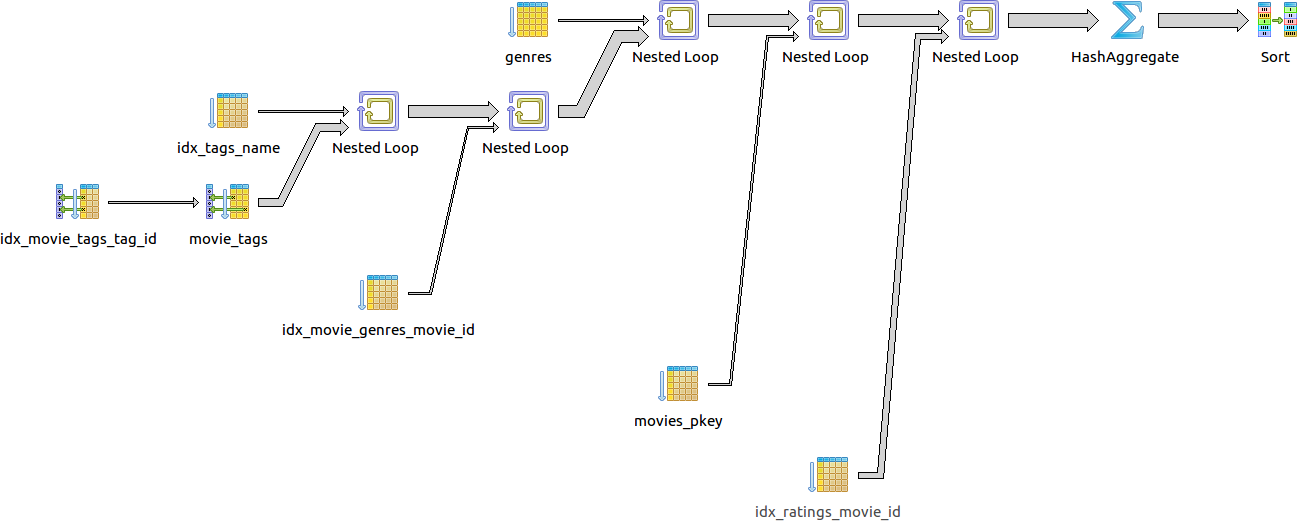
select m.id, m.title, avg(r.rating)
from movies m
join movie_genres gm on (gm.movie_id = m.id)
join genres g on (g.id = gm.genre_id)
join movie_tags tm on (tm.movie_id = m.id)
join tags t on (t.id = tm.tag_id)
join ratings r on (r.movie_id = m.id)
where lower(g.name) = lower('Comedy')
and lower(t.name) like lower('Zombie%')
group by m.id, m.title
order by avg(r.rating) desc;
Total query runtime: 10.9 secs
60 строк получено.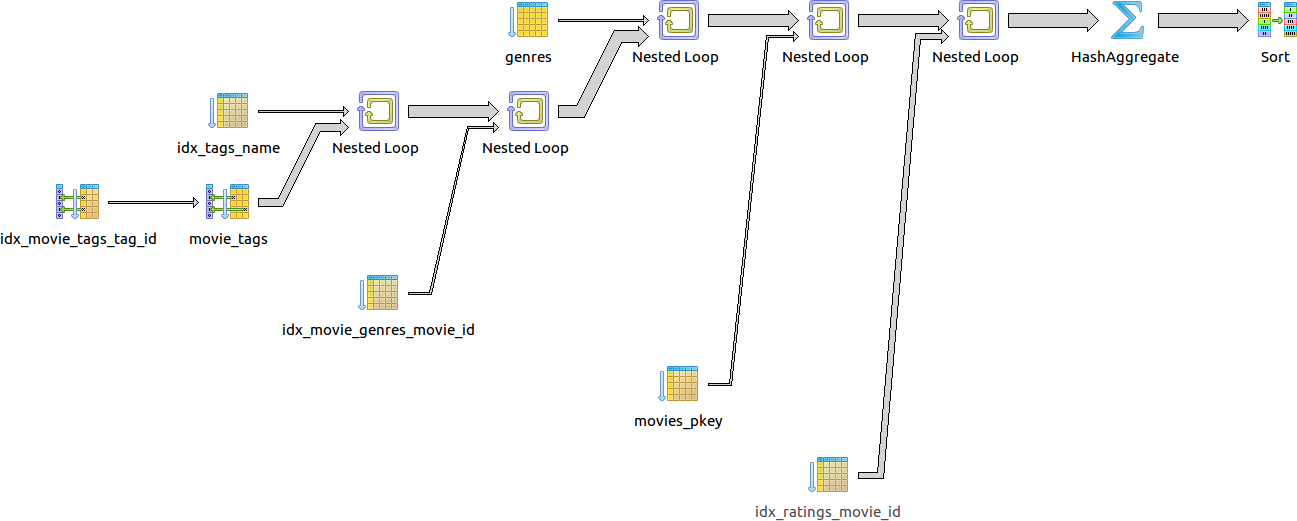
select m.id, m.title, avg(r.rating)
from (
select m.id, m.title
from movies m
join movie_genres gm on (gm.movie_id = m.id)
join genres g on (g.id = gm.genre_id)
join movie_tags tm on (tm.movie_id = m.id)
join tags t on (t.id = tm.tag_id)
where lower(g.name) = lower('Comedy')
and lower(t.name) like lower('Zombie%')
group by m.id
) m
join ratings r on (r.movie_id = m.id)
group by m.id, m.title
order by avg(r.rating) desc;
Total query runtime: 486 msec
60 строк получено.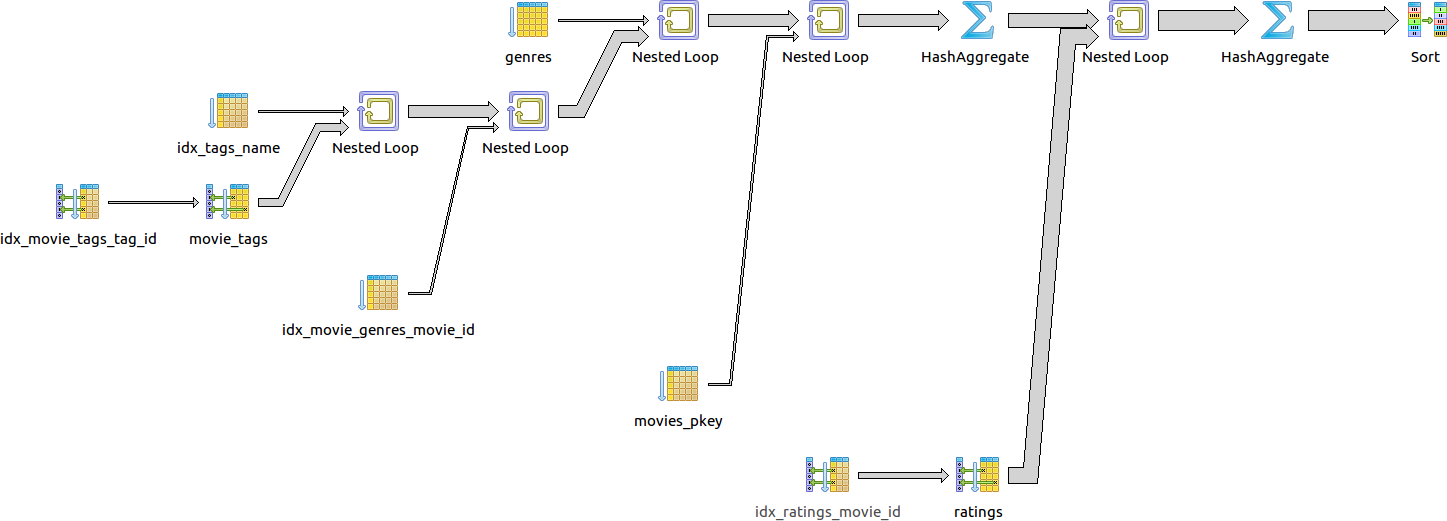
CREATE INDEX idx_ratings_movie_id_rating ON ratings (movie_id, rating);
VACUUM;
select m.id, m.title, avg(r.rating)
from (
select m.id, m.title
from movies m
join movie_genres gm on (gm.movie_id = m.id)
join genres g on (g.id = gm.genre_id)
join movie_tags tm on (tm.movie_id = m.id)
join tags t on (t.id = tm.tag_id)
where lower(g.name) = lower('Comedy')
and lower(t.name) like lower('Zombie%')
group by m.id
) m
join ratings r on (r.movie_id = m.id)
group by m.id, m.title
order by avg(r.rating) desc;
Total query runtime: 82 msec
60 строк получено.